In this tutorial we shall discuss about:
1. User should be able to tweet to all of his followers who has >10M followers.
2. Timeline:
1. Home Time line: It has all the tweets that you are following.
2. User Time line: This is specific to specific user timeline
3. Search Time line: Here user will search for a keyword, user should be able to get all the items in his timeline.
3. Trends
6.1 Characteristic of twitter:
Twitter has 300+M user
Twitter gets about 600 tweets/sec [write]
Twitter gets about 60000 reads/sec [read]
Hence the twitter is read heavy. Twitter can have eventual consistency. As twitter supports 140 characters per tweet, there is no need to worry about storage as the price has been reduced, we need to consider scalability to support 60000 reads/sec.
6.2 How to get all the tweets for a particular user?
As twitter is read heavy, we need a system that loads the data faster. For this we can use Redis to store the tweets. The structure can be as shown below:
user_id -> user_tweets [1, 2, 3, …]
Tweet_id -> tweet “Hello world”
Here first we search for the user_id with the help of user name and get all the ID of the tweets.
Then we go to the tweet_id table to get all the actual tweets mapping to that user. Then with the help of additional metadata like “created_time” we can chronologically sort the data.
6.3 How to get the data for Home timeline?
Home timeline will have all the tweets where the person is following.
For this, first get all the followers the user is following.
Then for each follower get all the latest tweets.
Then merge all the tweets and shows the tweets sorted by time.
6.4 But is this scalable?
Suppose an average user is following around 50 pages, making 50 queries all the time and displaying is a time consumable task. Hence as the users increases the service will not be scalable.
Hence we need to come up with a new solution. Below another solution:
This approach is called as Fanout approach.
Suppose if a user is followed by 10 people. The fanout approach works as below:
1. When that user pushes a tweet, then first write the tweet in the DB.
2. Then write the same tweet in the user timeline. [discussed above].
3. Then fanout the user tweet to all of his followers. Thus the follower home timeline will already be having the persons tweet present.
Hence whenever a person opens twitter, his home timeline will be having all the tweets from the pages/persons he is following.
This approach has a problem. Consider a user is a celebrity and has been followed by millions of users, we cannot possibly update all of the followers timeline, it will take time.
So what we do is, we maintain another table associated with every user called as “celebrity_table”. This table will update every time a user has followed a celebrity. So when the user login to twitter, he will get tweets as generated in the previous step, then the Redis checks if he follows any celebrity, if he follows, Redis will get the tweet from the celebrity and display in this home timeline.
This making the system faster.
6.5 How to calculate and display trends?
Twitter will calculate the volume of the tweet and time taken to generate that tweet to know if the topic is trending or not.
For example:
1000 tweets in 5min is interesting that 10000 tweets in a month. To process tons of data you can use Apache Strom or Heron.
6.6 How search timeline works?
Twitter uses Early Bird concept. Every time when a tweet is generated, those words are converted into hashtags, and in-turn will be mapped to different tweets that has those words.
Then when a user searches for a word, we get that word and displays all the tweets having that word.
Twitter System Design and data flow:
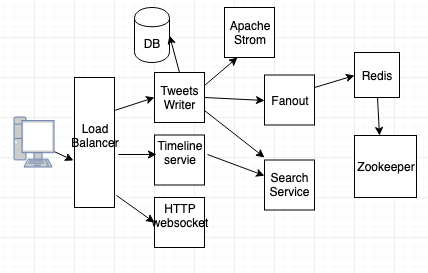
From when image above, when a user tweets, that tweet will reach the load-balancer. Then load-balancer will distributed the tweet to a Tweet writer. This service will write the tweet into the database, and sends it to Apache Strom for computing the trending topic. Then it is also sent to fanout service. After that it will send it to search service also.
When the user search for a word, the search API will first hit the load-balancer. Then it is forwarded to timeline service. Then it is forwarded to search service. The search service will get all the data form different nodes or datacentres and sends the data to the application.
When the user requests for his user timeline, then the request will be going to Redis to get all the tweets that the user has tweeted.
HTTP Push service is used to keep the connection open for iPhone or android applications.
As the system is distributed across multiple servers, we need a master that will co-ordinate with all the servers and check if the server is online or offline. We can use Zookeeper.
{kind=link}
{kind=link}